






标题:《分布式实时排序:技术原理与实现策略解析》
随着大数据时代的到来,数据量呈爆炸式增长,如何对海量数据进行高效、准确的排序成为了一个重要的课题。分布式实时排序技术应运而生,它能够满足大规模数据处理的需求,为各种应用场景提供实时、高效的排序服务。本文将深入探讨分布式实时排序的原理、实现策略以及相关技术,以期为相关领域的研究和实践提供参考。
一、分布式实时排序的背景与意义
- 背景介绍
随着互联网、物联网、云计算等技术的快速发展,数据量呈指数级增长。传统的单机排序方法在处理大规模数据时,面临着计算资源瓶颈、响应速度慢等问题。为了解决这些问题,分布式实时排序技术应运而生。
- 意义
(1)提高数据处理效率:分布式实时排序技术可以将数据分布到多个节点上并行处理,从而提高数据处理效率。
(2)降低资源消耗:通过分布式计算,可以降低单个节点的资源消耗,提高资源利用率。
(3)满足实时性需求:分布式实时排序技术能够满足实时性需求,为各种应用场景提供高效、准确的排序服务。
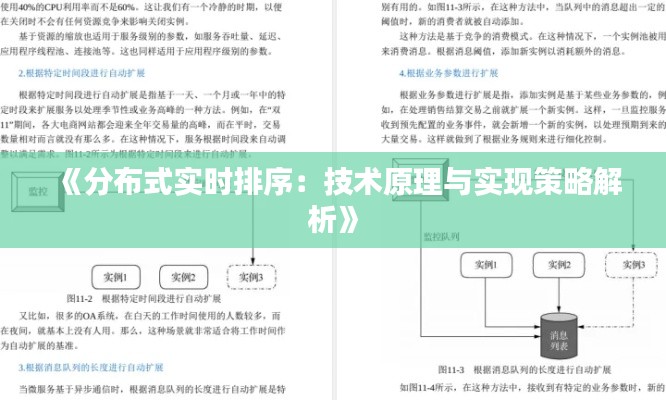
二、分布式实时排序原理
- 分布式计算模型
分布式实时排序技术通常采用分布式计算模型,将数据分布到多个节点上进行处理。常见的分布式计算模型有MapReduce、Spark等。
- 数据划分与传输
(1)数据划分:将大规模数据划分为多个子集,每个子集包含部分数据。
(2)数据传输:将数据子集传输到对应的节点上,以便进行并行处理。
- 数据排序
(1)局部排序:在各个节点上对数据子集进行局部排序。
(2)全局排序:将局部排序后的数据子集进行合并,实现全局排序。
- 数据合并与优化
(1)数据合并:将局部排序后的数据子集进行合并,形成全局排序结果。
(2)数据优化:对全局排序结果进行优化,提高排序效率。
三、分布式实时排序实现策略
- 数据划分策略
(1)哈希划分:根据数据键值进行哈希运算,将数据划分到不同的节点上。
(2)轮询划分:按照节点顺序依次将数据划分到各个节点上。

- 数据传输策略
(1)数据压缩:在传输过程中对数据进行压缩,减少传输数据量。
(2)数据缓存:在节点间建立数据缓存机制,提高数据传输效率。
- 数据排序策略
(1)快速排序:采用快速排序算法对数据子集进行局部排序。
(2)归并排序:采用归并排序算法对数据子集进行局部排序。
- 数据合并与优化策略
(1)多路归并:采用多路归并算法对全局排序结果进行合并。
(2)内存优化:在合并过程中,对数据进行内存优化,提高合并效率。
四、总结
分布式实时排序技术在处理大规模数据时具有显著优势,能够满足实时性、高效性的需求。本文对分布式实时排序的原理、实现策略以及相关技术进行了深入探讨,以期为相关领域的研究和实践提供参考。随着技术的不断发展,分布式实时排序技术将在更多领域发挥重要作用。
转载请注明来自南京强彩光电科技有限公司,本文标题:《《分布式实时排序:技术原理与实现策略解析》》






 苏ICP备18007744号-2
苏ICP备18007744号-2